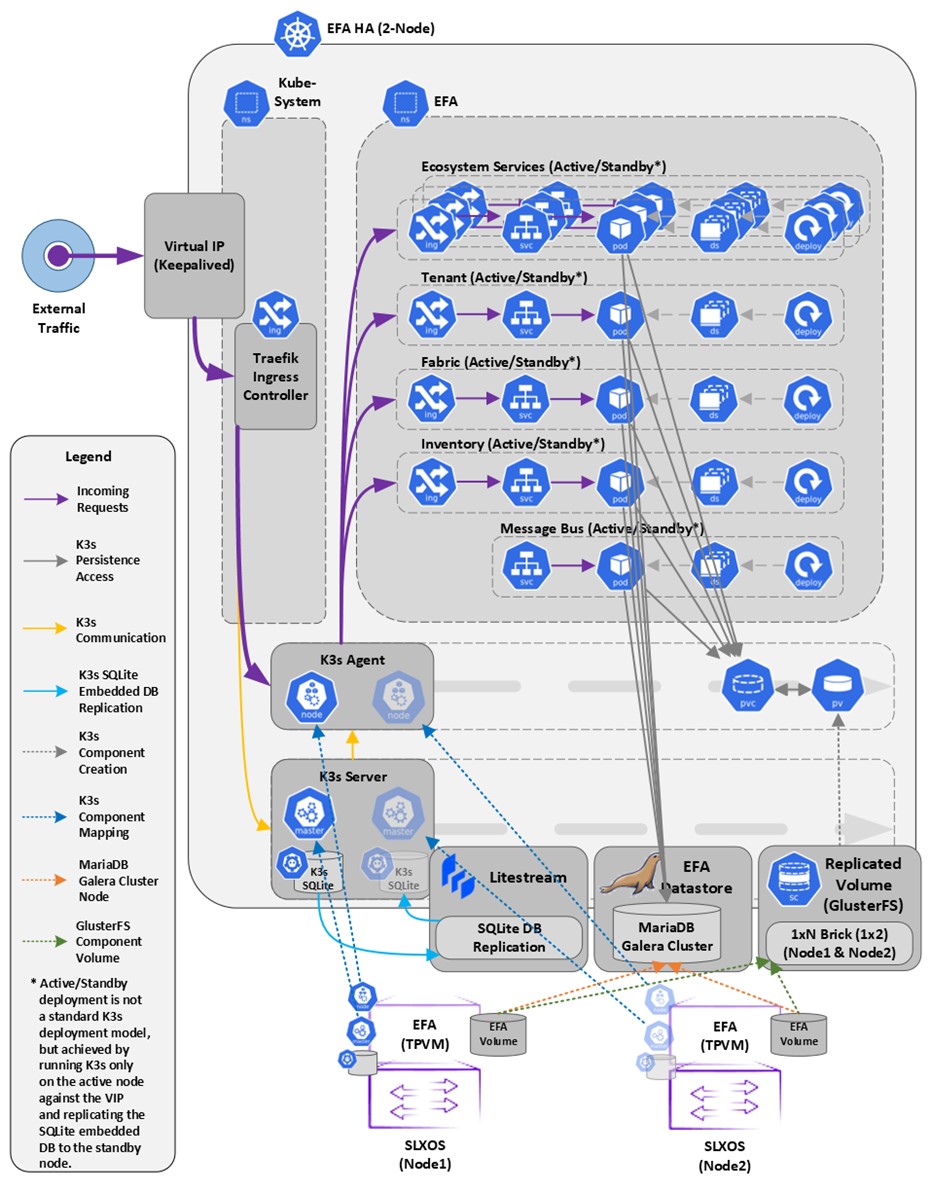
You can deploy EFA in a two-node cluster
for high availability.
Overview
A high-availability cluster is a group of servers that provide continuous up time, or
at least minimum down time, for the applications on the servers in the group. If an
application on one server fails, another server in the cluster maintains the
availability of the application.
In the following diagram, EFA is deployed in the TPVM running on SLX-OS. The two EFA instances
are clustered and configured with one IP address, so that clients need to reach only
one endpoint. All EFA services are installed on each node. The node on which EFA is
installed is the active node and processes all requests. The other node is the
standby. The standby node runs processes all the requests when the active node
fails.
Two-node high-availability
deployment
All operations provided by EFA services must be idempotent, meaning they produce the
same result for multiple identical requests or operations. For more information, see
the "Idempotency" section of the
Extreme Fabric Automation Administration
Guide, 2.7.0
.
EFA uses the following services to implement an HA deployment:
Keepalived (VRRP) – It is a program which
runs on both nodes. The active node frequently sends VRRP packets to the standby
node. If the active node stops sending the packets, keepalived on the standby
assume the active role. Thus, the standby node becomes the active node. Each
state change runs a keepalived notify script containing logic to ensure EFA‘s
continued operation after a failure. With a two-node cluster, a ”split-brain”
may occur due to a network partition which leads to two active nodes. When the
network recovers, VRRP establishes a single active node that determines the
state of EFA.
K3s – In EFA 2.7.0, a k3s server runs on the
active node. Kubernetes state is stored in SQLite and is synced in real-time to
the standby node using a dedicated daemon, litestream. On a failover, the
keepalive notify script on the new active node reconstructs the Kubernetes
SQLite DB from the synced state and starts the k3s. In EFA 2.7.0, k3s runs on
one node at a time, not on both nodes and hence the HA cluster looks like a
single-node cluster, however, the HA cluster ties itself to the
keepalived-managed virtual IP.
MariaDB and Galera – EFA business states (device, fabric, and tenant
registrations and configuration) are stored in a set of databases managed by
MariaDB. Both the nodes run a MariaDB server, and the Galera clustering
technology is used to keep the business state in sync on both the nodes during
normal operation.
Glusterfs – This is a clustering filesystem
used to store EFA‘s log files, various certificates, and subinterface
definitions. A daemon runs on both the nodes which seamlessly syncs several
directories.
Note
Although Kubernetes run as a single-node cluster tied to the virtual IP, EFA CLIs still
operate correctly when they are run from active or standby node. Commands
are converted to REST and issued over HTTPS to the ingress controller via
the virtual IP tied to the active node.
EFA 2.7.0 de-emphasizes Kubernetes-specific outputs in its various informational CLIs. The SLX
show efa
status command now more closely matches the TPVM efa status command.
The efa status command
becomes more conservative when you declare the EFA as fully operational. It confirms
the following:
For the active node:
All enabled EFA services are reporting Ready
Kubernetes state is consistent with all the
enabled EFA services (for example, service endpoints exist)
The host is a member of the Galera or MariaDB cluster
For the standby node:
It is reachable via SSH from the active
node
It is a member of the Galera or MariaDB cluster
For both the nodes:
The Galera cluster size is 2 if both the nodes are up, and the cluster
size is >= 1 if the standby node is down.
The efactl utility is updated
in the following ways:
efactl start waits for all the started services to report Ready
before terminating. You can achieve an asynchronous operation by backgrounding
the command from the shell.
efactl stop-service
terminates all the selected EFA services. If you restart the EFA cluster, run a
subsequent efactl
start-service command to restart the stopped services.
PV: Persistent Volume
A piece of storage in the
cluster that was provisioned by an administrator.
PVC: Persistent Volume Claims
A request for storage,
similar to how a Pod requests compute resources.
Brick
The basic unit of storage in
GlusterFS, represented by an export directory on a server in the trusted
storage pool.
SC: Storage Class
A description of the
“classes” of storage in a Kubernetes realm.
SVC: Kubernetes Service
A logical set of Pods and a
policy by which to access them.
ING: Kubernetes Ingress
A collection of routing rules
that govern how external users access services running in a Kubernetes
cluster.
RS: Kubernetes Replica Sets
Ensures how many replicas of
a Pod should be running.
K3s
Manages the life cycle of the
EFA services in failover or fallback scenarios.
Traefik
An embedded ingress
controller (load balancer) packaged with K3s.
GlusterFS
A high-availability
replicated volume that maintains the persistent storage for the K3s cluster,
the EFA database, and EFA logs.
MariaDB
A database service deployed
outside of the K3s cluster in active-standby mode.
RabbitMQ
A messaging service deployed
in the cluster in active-active mode.
Services in high-availability mode
EFA services running on K3s are in active-standby mode.