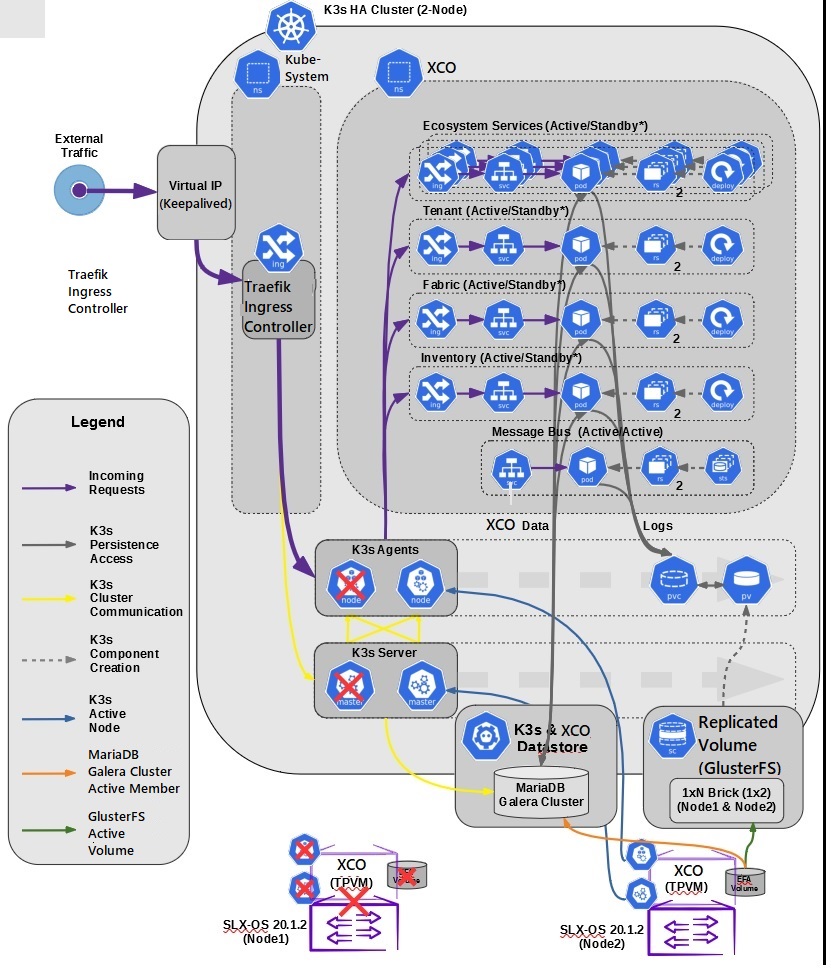
A high-availability cluster is a group of servers that provide continuous up time or minimum down time for the applications on the servers in the group. If an application on one server fails, another server in the cluster maintains the availability of the application.
In the following diagram, XCO is deployed on the Server. The two XCO instances are clustered and configured with one IP address ensuring that clients need to reach only one endpoint. All XCO services are installed on each node. The node on which XCO is installed is the active node and processes all requests. The other node is the standby node that processes all the requests when the active node fails.
All operations provided by XCO services must be idempotent, meaning they produce the same result for multiple identical requests or operations. For more information, see the "Idempotency" section in the ExtremeCloud Orchestrator CLI Administration Guide, 3.2.0 .
XCO uses the following services to implement an HA deployment:

Note
Although Kubernetes run as a single-node cluster tied to the virtual IP, XCO CLIs still operate correctly when they run from active or standby node. Commands are converted to REST and run over HTTPS to the ingress controller via the virtual IP tied to the active node.
The efa status confirms the following:
NH-1# show efa status
===================================================
EFA version details
===================================================
Version : 3.1.0
Build: 109
Time Stamp: 22-10-25:12:45:44
Mode: Secure
Deployment Type: multi-node
Deployment Platform: TPVM
Deployment Suite: Fabric Automation
Virtual IP: 10.20.246.103
Node IPs: 10.20.246.101,10.20.246.102
--- Time Elapsed: 8.512402ms ---
===================================================
EFA Status
===================================================
+-----------+---------+--------+---------------+
| Node Name | Role | Status | IP |
+-----------+---------+--------+---------------+
| tpvm2 | active | up | 10.20.246.102 |
+-----------+---------+--------+---------------+
| tpvm | standby | up | 10.20.246.101 |
+-----------+---------+--------+---------------+
--- Time Elapsed: 19.168973841s --