XCO high availability provides for uninterrupted service in several different scenarios.
For information about deploying XCO for high availability, see the ExtremeCloud Orchestrator Deployment Guide, 3.2.1 .
When an SLX device fails, the SLX-OS and the XCO services running on TPVM go down for the failed node. The time it takes for failover to the standby node varies depending on whether the K3s agent node is actively running the XCO services. The following image depicts a scenario in which one SLX device fails.
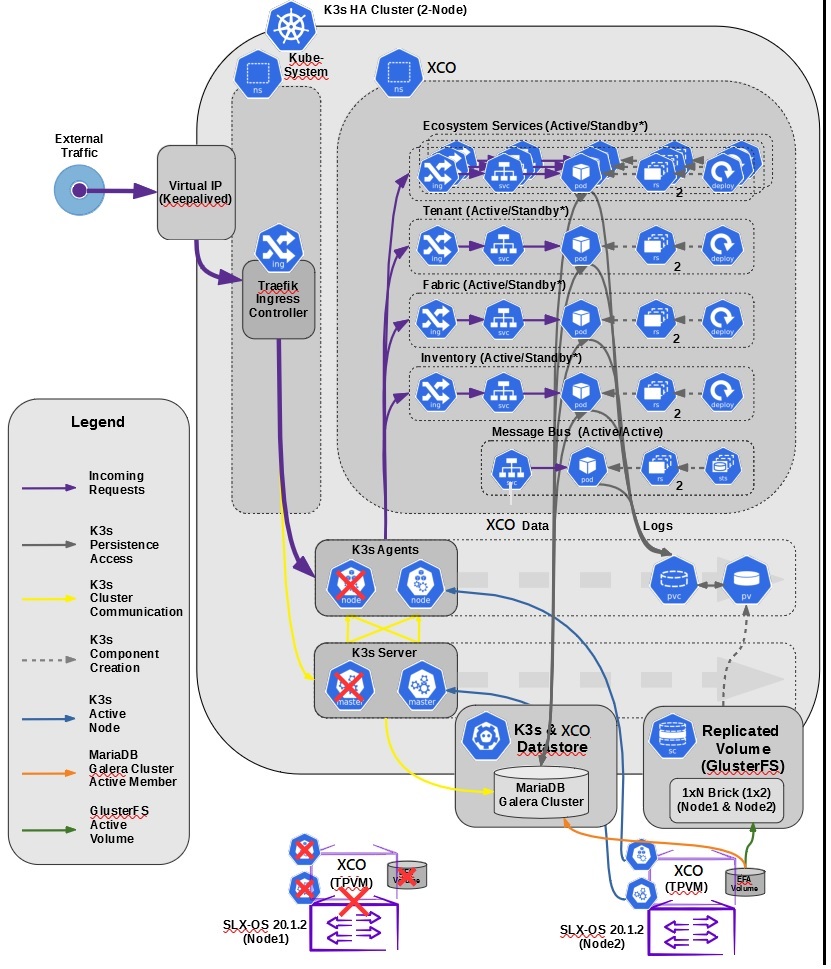
When the K3s agent node is actively running XCO services on a node that fails, K3s initiates failover and starts the XCO services on the standby node. Failover is complete when XCO services are running on the newly active K3s agent node (node 2).
Because the GlusterFS replicated volume remains available during failover, the K3s cluster data store and the XCO data store remain operational.
When the failed node is again operational, it becomes the standby node. The K3s agent node continues to run XCO services from node 2. When both nodes are up and K3s is running, all services fetch the latest data from devices to ensure that XCO has the latest configurations.
When the K3s agent node is the standby and is not running XCO services, no failover actions occur if this node fails. XCO services continue to run on the active node without interruption.
The TPVM failure scenario is similar to that of the SLX device failure scenario. The only difference is that SLX-OS continues to operate.
In the unlikely event that both nodes in the cluster fail at the same time (for reasons such as a power failure or the simultaneous reboot of SLX devices), XCO has built-in recovery functionality. If the cluster is not automatically recovered within 10 minutes of power being restored or within 10 minutes of the TPVM being rebooted, then you can manually recover the cluster.