Configuration and network monitoring are two tasks a network administrator faces as a network grows in terms of the number of managed nodes (controllers, service platforms, wireless devices etc.). Such scalability requirements lead network administrators to look for managing and monitoring each node from a single centralized management entity. NX service platforms provide centralized management solution in the form of centralized management profile that can be shared by any single controller or service platform cluster member. This eliminates dedicating a management entity to manage all cluster members and eliminates a single point of failure.
A cluster (or redundancy group) is a set of controllers or service platforms (nodes) uniquely defined by a profile configuration. Within the cluster, members discover and establish connections to other members and provide wireless network self-healing support in the event of member's failure.
A cluster's load balance is typically distributed evenly amongst its members. An administrator needs to define how often the profile is load balanced for radio distribution, as radios can come and go and members join and exit the cluster.
To define a cluster configuration for use with a profile:
Select the tab from the Web UI.
A screen displays where the profile's cluster and AP load balancing configuration can bet set.
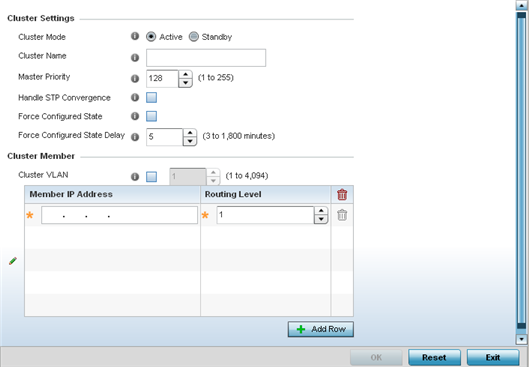
| Cluster Mode | A member can be in either an Active or Standby mode. All active member can adopt access points. Standby members only adopt access points when an active member has failed or sees an access point not adopted by a controller or service platform. The default cluster mode is Active and enabled for use with the profile. |
| Cluster Name | Define a name for the cluster name unique to its configuration or profile support requirements. The name cannot exceed 64 characters. |
| Master Priority | Set a priority value from 1 - 255, with the higher value given higher priority. This configuration is the device‘s priority to become the cluster master. In a cluster environment, one device from the cluster is elected as the cluster master. The master priority setting is the device‘s priority to become cluster master. The active primary controller has the higher master priority. The default value is 128. |
| Handle STP Convergence | Select the check box to enable Spanning Tree Protocol (STP) convergence for the controller or service platform. In general, this protocol is enabled in layer 2 networks to prevent network looping. Spanning Tree is a network layer protocol that ensures a loop-free topology in a mesh network of inter-connected layer 2 cluster members. The spanning tree protocol disables redundant connections and uses the least costly path to maintain a connection between any two controllers or service platforms in the network. If enabled, the network forwards data only after STP convergence. Enabling STP convergence delays the redundancy state machine execution until the STP convergence is completed (the standard protocol value for STP convergence is 50 seconds). Delaying the state machine is important to load balance APs at startup. The default setting is disabled. |
| Force Configured State | Select the check box to enable this cluster member to take over for an active member if it were to fail. A standby controller or service platform takes over APs adopted by the failed member. If the failed cluster member were to come available again, the active member starts a timer based on the Auto Revert Delay interval. At the expiration of the Auto Revert Delay, the standby member releases all adopted APs and goes back to a monitoring mode. The Auto Revert Delay timer is stopped and restarted if the active member goes down and comes up during the Auto Revert Delay interval. The default value is disabled. |
| Force Configured State Delay | Specify a delay interval in either Seconds (1 - 1,800) or Minutes (1 - 30). This is the interval a standby cluster member waits before releasing adopted APs and goes back to a monitoring mode when a controller becomes active again after a failure. The default interval is 5 seconds. |

Note
Specify the IP Addresses of the VLAN's cluster members using the IP Address table.