Multiple Rings Sharing a Common Link shows an example of a multiple ring topology that uses the EAPSEAPS (Extreme Automatic Protection Switching) common link feature to provide redundancy for the switches that connect the rings.
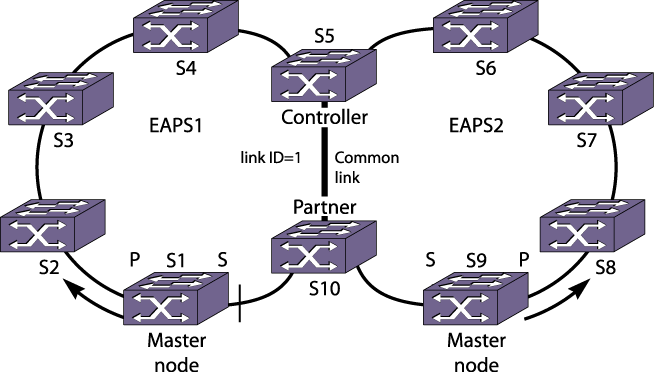
An EAPS common link is a physical link that carries overlapping VLAN (Virtual LAN)VLANs that are protected by more than one EAPS domain.
In the example shown earlier, switch S5 could be a single point of failure. If switch S5 were to go down, users on Ring 1 would not be able to communicate with users on Ring 2. To make the network more resilient, you can add another switch. A second switch, S10, connects to both rings and to S5 through a common link, which is common to both rings.
The EAPS common link requires special configuration to prevent a loop that spans both rings. The software entity that requires configuration is the eaps shared-port, so the common link feature is sometimes called the shared port feature.

Note
If the shared port is not configured and the common link goes down, a superloop between the multiple EAPS domains occurs.The correct EAPS common link configuration requires an EAPS shared port at each end of the common link. The role of the shared port (and switch) at each end of the common link must be configured as either controller or partner. Each common link requires one controller and one partner for each EAPS domain. Typically the controller and partner nodes are distribution or core switches. A controller or partner can also perform the role of master or transit node within its EAPS domain.
During normal operation, the master node on each ring protects the ring as described in EAPS Single Ring Topology. The controller and partner nodes work together to protect the overlapping VLANs from problems caused by a common link failure or a failed controller (see Master Node Operation in a Multiple Ring Topology).
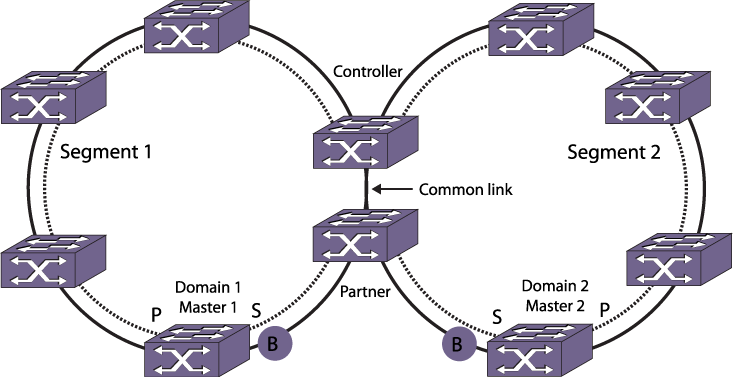
If a link failure occurs in one of the outer rings, only a single EAPS domain is affected. The EAPS master detects the failure in its domain, and converges around the failure. In this case, the controller does not take any blocking action, and EAPS domains on other rings are not affected. Likewise, when the link is restored, only the local EAPS domain is affected. The controller and any EAPS domains on other rings are not affected, and continue forwarding traffic normally.
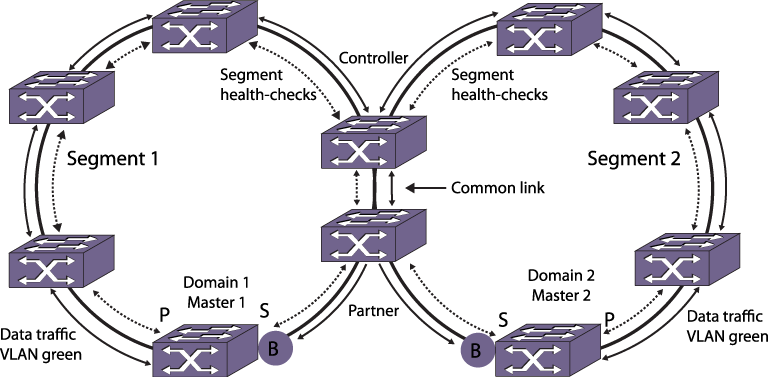
To detect common-link faults, the controller and partner nodes send segment health check messages at one-second intervals to each other through each segment. A segment is the ring communication path between the controller and partner. The common link completes the ring, but it is a separate entity from the segment. To discover segments and their up or down status, segment health-check messages are sent from controller to partner, and also from partner to controller (see Segment Health-Check Messages).
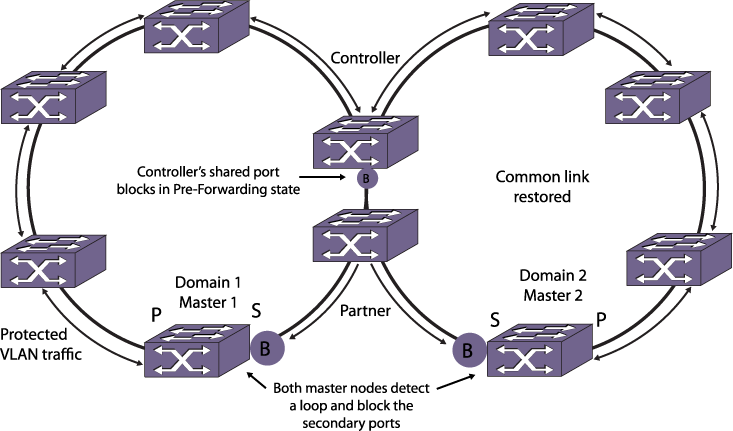
With one exception, when a common link fails, each master node detects the failure and unblocks its secondary port, as shown in Common Link Failure.
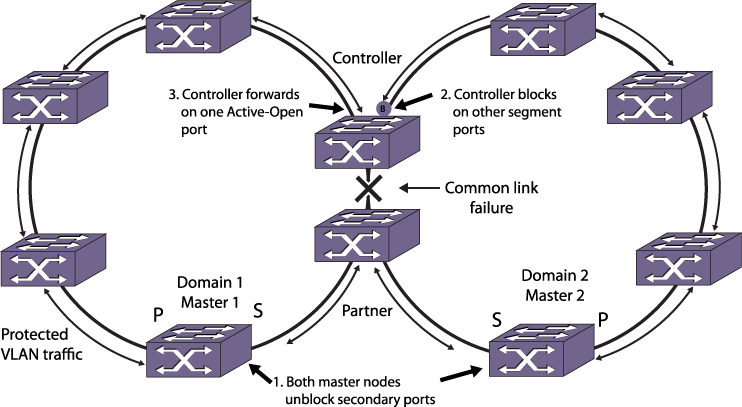
Because the secondary port of each master node is now unblocked, the new topology introduces a broadcast loop spanning the outer rings.
Note
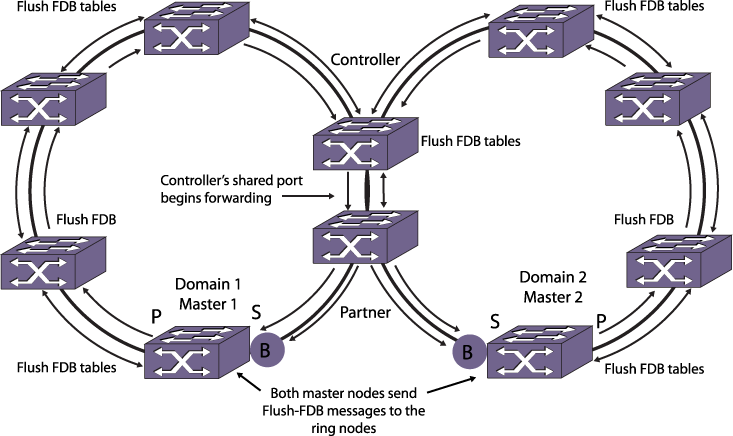
When a controller goes into or out of the blocking state, the controller sends a flush-fdb message to flush the FDB (forwarding database) in each of the switches in its segments. In a network with multiple EAPS ports in the blocking state, the flush-fdb message gets propagated across the boundaries of the EAPS domains.Note
If CFM is not used, it is recommended to have a direct Link connected between EAPS Controller Node and EAPS Partner Node.The exception mentioned above occurs when the partner node is also a master node, and the shared port that fails is configured as a primary port. In this situation, the master node waits for a link-down PDU from the controller node before opening the secondary port. This delay prevents a loop that might otherwise develop if the master/partner node detects the link failure before the controller node.
Note
If the common link and a ring link fail, and if the common link restores before the ring link, traffic down time can be as long as three seconds. This extended delay is required to prevent loops during the recovery of multiple failed links.When a common link recovers, each master node detects that the ring is complete and immediately blocks their secondary ports. The controller also detects the recovery and puts its shared port to the common link into a temporary blocking state called pre-forwarding as shown in Common Link in Pre-Forwarding State.
Because the topology has changed, the EAPS nodes must learn the new traffic paths. Each master node notifies all switches in their domain to clear their FDB tables, and traditional Ethernet bridge learning and forwarding mechanisms establish the new traffic paths. Once the controller receives flush-fdb messages for all of its connected EAPS domains, the controller shared-port state for the common link changes to forwarding, the controller state changes to Ready, and traffic flows normally as shown in Common-Link Restored.
 Print
this page
Print
this page Email this topic
Email this topic Feedback
Feedback View PDF
View PDF Download EPUB
Download EPUB