If a daisy chain is broken, or if a ring is broken in two places, it is possible to form two separate active stack topologies. This results in a dual master situation, as shown in the following example .
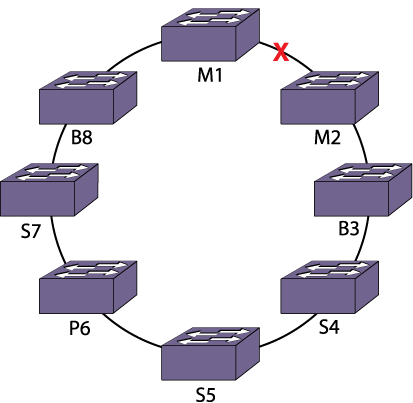
| P6 | Node 6 is powered off |
| M | Master nodes |
| B | Backup nodes |
| S | Standby nodes |
| X | Indicates the broken link |
In the example, a link was broken while a node in the ring was powered off. The broken link formerly connected the original master (M1) and backup (M2) nodes of a single active topology.
All nodes in the stack except the powered-off node are in the active topology and all nodes are configured to be master-capable. Nodes 1, 7 and 8 form an active topology and nodes 2, 3, 4, and 5 form another active topology. Node M2 immediately transitions from backup to master node role. Nodes B8 and B3 are elected in their respective active topologies as backup nodes.
If the backup node is on one stack and the master node is on the other, the backup node becomes a master node because the situation is similar to that of master failure. Because both stacks are configured to operate as a single stack, there is confusion in your networks. For example, all of the switch‘s configured IP addresses appear to be duplicated. The management IP address also appears to be duplicated since that address applies to the entire original stack.
To help mitigate the dual master problem, you can configure master-capability so as to prevent some nodes in the stack from operating in backup or master node roles. In addition, you can force all nodes in the (broken) stack topology to restart and come up as not master-capable for the life of that restart. The save configuration {primary | secondary | existing-config | new-config} command saves the configuration on all nodes in the active topology.
Standby nodes that exist in a severed stack segment that does not contain either the original master or backup node do not attempt to become the master node. Instead, these nodes reboot. After rebooting, however, a master election process occurs among the nodes on this broken segment, resulting in a dual master situation.
Dual master conditions are also possible when two non-adjacent nodes in a ring or a single (middle) node in a daisy chain reboot.
When the rebooting nodes have sufficiently recovered, or when a severed stack is rejoined, the dual master condition is resolved, resulting in the reboot of one of the master nodes. All standby and backup nodes that had been acquired by the losing master node also reboot.
 Print
this page
Print
this page Email this topic
Email this topic Feedback
Feedback View PDF
View PDF Download EPUB
Download EPUB